

The double helix structure of Deoxyribose Nucleic Acid (DNA) was established in 1953, in a paper published by James Watson and Francis Crick, working at the Cavendish Laboratory at Cambridge University. In this post, I’ve provided a beginner’s guide to genetics, with a fairly simple outline of how the genetic code carried on DNA is translated into a human, or indeed any other living organism.
Let’s get one thing out of the way at the start though: Watson and Crick did not discover DNA. All the hard work on that was done by Rosalind Franklin, the ‘dark lady of DNA’ as she was disparagingly labelled by Watson. Franklin also worked at the Cavendish Laboratory, spending years using crystallography techniques to establish the structure of DNA. Watson and Crick were, as far as DNA is concerned, model-makers. Watson came up with the idea of the double helix after seeing ‘photograph 51’ in a lecture by Franklin. He and Crick took Franklin’s crystallography images and imagined a potential structure for DNA: a double helix. It was a lucky guess; they were right. Franklin had already been on to this, and had suspected this double helical structure, but wanted to do more work to prove it was right. Watson and Crick received a Nobel prize for their work in 1962. Franklin received almost no recognition for her work within her short, 37-year life. There were calls for her to be recognised with a Nobel prize after her death, but after posthumous Nobels had been discontinued in 1974. When I studied genetics at university in the 70s, Rosalind Franklin was never mentioned.

So what was it that Franklin had discovered? Her crystallography work examined a very large molecule, which occupied much of the nucleus of all cells, both eukaryotic (all animals and plants from single-celled amoebae to trees and humans) and prokaryotic (bacteria). The ‘backbone’ of this DNA molecule contains a sugar called deoxyribose, joined to a phosphate ion, each of which contains one phosphorus atom and four oxygen atoms. This phosphate-deoxyribose pair can join to other identical phosphate-deoxyribose pairs ad infinitum, forming a strongly-bonded chain of any length. Our genetic code is carried on these deoxyribose-phosphate chains through a sequence of small molecules, called organic bases, stuck along the chain. A ‘base’ is a molecule that displays the chemical properties of an alkali rather than an acid, but that’s not especially relevant here.
There are just four of these bases in DNA, called adenine, cytosine, thymine and guanine. Each of these bases chemically bonds to only one of the other four bases, so there are four possible base pairs: adenine with thymine, thymine with adenine, cytosine with guanine, guanine with cytosine. So from one of these phosphate-deoxyribose chains with a sequence of bases attached, a mirror image chain can be constructed, based on the permissible base pairs. So DNA is made up of two sugar-phosphate backbone chains with a series of bases dotted along each chain, paired to their partner bases along a second sugar-phosphate chain, forming a structure like a ladder, where the paired bases form the rungs. These two strands are twisted together into the now famous double helix structure. The sequence of these base pairs is the genetic code for an organism, or genome. There are around three billion base pairs in a human genome – more than enough to code for all the proteins needed to determine what we are and how we’re put together.
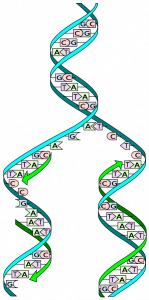
From a single egg cell, this DNA sequence is replicated many times over, through a process called mitosis. Basically, that means the DNA double helix unravels and the base pairs are split, producing two separate strands. Enzymes in the egg then use the sequence of bases on each of these single strands to build another strand from the four bases, phosphate and deoxyribose molecules (that are just floating about), which when complete, twists back into a new double helix. And so from one molecule of DNA, two identical molecules are produced. This process continues whenever a cell divides, until an entire organism is formed. Thus every cell in every animal or plant contains the entire genetic code (or genome) for that organism.
So how do we get from this genetic code, carried identically in every cell in our bodies, to the huge variety of functions, structure and purpose that our cells have, working together to create an entire organism? All of what we are is achieved by DNA coding for the production of proteins. In order for our DNA to do this, it has to open up the spiral to expose a line of unpaired bases. Different bits of this genome will open up in different kinds of cells to programme for the production of different proteins. That’s how cells end up with different structures and functions. This, and all these other metabolic processes, are brought about by special protein catalysts called enzymes.
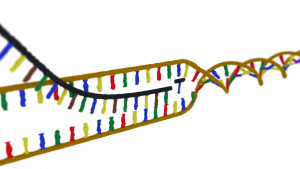
Now this is where RNA comes in: DNA’s little, but harder-working, sister molecule. Ribose nucleic acid (RNA) is very similar in structure to DNA, with a sugar-phosphate backbone and a sequence of bases. The sugar in the backbone however is ribose rather than deoxyribose, and uracil replaces thymine in the four bases, which makes it sound like a re-formed rock band. Strands of RNA are single however, much shorter than DNA, and not twisted into a helical structure.
After the DNA has opened up, exposing unpaired bases, something called messenger RNA (m-RNA) is made from the exposed strand of DNA, copying that section of genetic code expressed as a sequence of bases into its own base sequence. This m-RNA molecule now moves from the cell nucleus to the cytoplasm (think of a cell as like an egg, with a nucleus in the centre and the cytoplasm surrounding it) where it attaches itself to a structure called a ribosome. Here, another type of RNA comes into play: transfer RNA (t-RNA). Transfer RNA has just three bases exposed on it, but is twisted into a loop and attached to an amino acid. Amino acids are the building blocks of proteins.
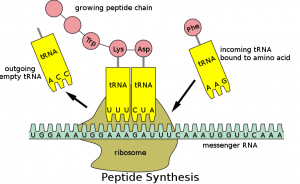
There are around 20 of these amino acids, about half of which we can synthesise in our bodies, the other half we get from the food we eat. There are also around 20 different types of t-RNA, one for each of the amino acids. Each one has a different triplet of bases at one end, carrying its amino acid at the other end. When the m-RNA gets to the ribosome, these t-RNA molecules plug their three bases into corresponding triplets of bases on the m-RNA molecule. This brings together the amino acids they’re carrying in an order determined by the sequence of bases on the m-RNA, which was of course programmed from the DNA. The amino acids now link up to create chains called peptides. Enzymes get to work on these peptide chains to join them together in very particular ways and hey presto, we have proteins.
Proteins are very complex, and often very large, chemicals made up of amino acid building blocks joined together in long, often branching and twisted, chains. Hair, skin, hormones, internal organs, animal cell walls, and pretty much all the structures in our bodies are made of protein. All other materials we’re made up from, starches, sugars, fats, bone, are made by enzymes.
Some of the proteins in our body are produced directly from this ribosomal code-breaking process, but many are made in a secondary way, by enzymes. Enzymes are incredibly important in making us what we are. Imagine you’re building a car manufacturing plant. The DNA is the instruction manual for building the robotic machinery that makes the cars. The team who use the instruction manual to make the robotic machines are the RNA. The robotic machines are the enzymes, which produce the car components, and assemble those components into cars. And we are the cars. Chemically, enzymes are catalysts that bring about very specific and complex chemical reactions in a way that made no sense at all when I was at university, but is now believed to have something to do with quantum tunnelling … but that’s another story.
And so there it is. Unravelling the mysteries of how we’re made didn’t emerge fully-formed from Rosalind Franklin’s photograph 51 of course, it took another couple of decades to work out the basics of how the genetic code gets decoded, with scientists still working on the details today. And those details could help us cure hereditary diseases, cancer, and more. They could prevent faults occurring in DNA replication and translation. They could even end the ageing process, perhaps. Imagine the consequences of that …